Clustering Audiology Data
Proceedings of the 19th Annual Belgian-Dutch Conference on Machine Learning (BeneLearn 2010),
Editors: Jan Ramon and Celine Vens and Kurt Driessens and Martijn Van Otterlo and Joaquin Vanschoren,
- May 2010
Associated documents :

In this paper we describe new results of
statistical and neural data mining of audiology
patient records, with the ultimate aim of
looking for factors influencing which patients
would most benefit from being fitted with a
hearing aid. We describe how a combination of
neural and statistical techniques can usefully
subdivide a set of patients into clusters, based
on their hearing thresholds at six different
frequencies, and then label the clusters with
meaningful text labels. In our first experiment
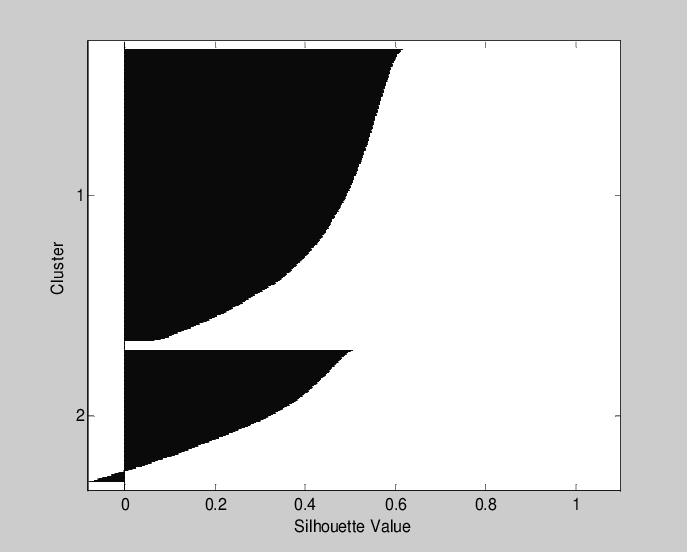
we cluster the patients based on similarities
between their audiograms using k-means
clustering, resulting in two main clusters. We
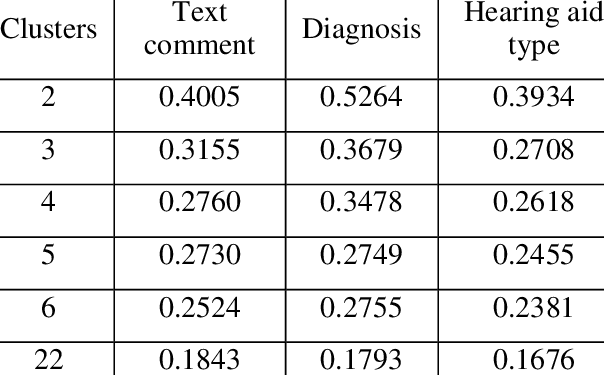
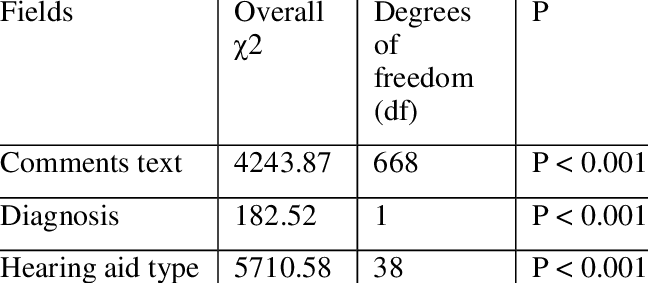
then use the chi-squared test to label each
cluster with the keywords selected from the
text comment, diagnosis and hearing aid type
associated with each patient which are most
typical (and atypical) of each cluster. In our
second experiment, we again cluster the
patients based on similarities between their
audiograms, but this time using a selforganizing map (SOM). Here the locations in
the resulting map, corresponding to individual
patients, are labeled with the type of hearing
aid selected for each patient. We demonstrate
that this automatic textual labeling addresses
well the heterogeneous character of medical
audiology records, since they consist of
numeric, structured and free text data.


@InProceedings{AOWH10,
author = {Anwar, Muhammad Naveed and Oakes, Michael Philip and Wermter, Stefan and Heinrich, Stefan},
title = {Clustering Audiology Data},
booktitle = {Proceedings of the 19th Annual Belgian-Dutch Conference on Machine Learning (BeneLearn 2010)},
journal = {None},
editors = {Jan Ramon and Celine Vens and Kurt Driessens and Martijn Van Otterlo and Joaquin Vanschoren},
number = {}
volume = {}
pages = {}
year = {2010},
month = {May},
publisher = {University of Leuven, BE},
doi = {None},
url = {None},
}