Grasping with flexible viewing-direction with a learned coordinate transformation network
5th IEEE-RAS International Conference on Humanoid Robots,
pages 253--258,
doi: 10.1109/ICHR.2005.1573576
- Dec 2005
Associated documents :


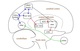
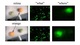
We present a neurally implemented control system
where a robot grasps an object while being guided by the visually
perceived position of the object. The system consists of three
parts operating in a series: (i) A simplified visual system with
a what-where pathway localizes the target object in the visual
field. (ii) A coordinate transformation network considers the
visually perceived object position and the camera pan-tilt angle to
compute the target position in a body-centered frame of reference,
as needed for motor action. (iii) This body-centered position
is then used by a reinforcement-trained network which docks
the robot at a table so that it can grasp the object. The novel
coordinate transformation network which we describe in detail
here allows for a complicated body geometry in which an agents
sensors such as a camera can be moved with respect to the
body, just like the human head and eyes can. The network is
trained, allowing a wide range of transformations that need not
be implemented by geometrical calculations


@InProceedings{WKW05,
author = {Weber, Cornelius and Karantzis, Konstantinos and Wermter, Stefan},
title = {Grasping with flexible viewing-direction with a learned coordinate transformation network},
booktitle = {5th IEEE-RAS International Conference on Humanoid Robots},
journal = {None},
editors = {}
number = {}
volume = {}
pages = {253--258},
year = {2005},
month = {Dec},
publisher = {IEEE},
doi = {10.1109/ICHR.2005.1573576},
}