Reusing Neural Speech Representations for Auditory Emotion Recognition
Proceedings of the Eighth International Joint Conference on Natural Language Processing,
Volume 1,
pages 423--430,
doi: 10.48550/arXiv.1803.11508
- Nov 2017

Associated documents :


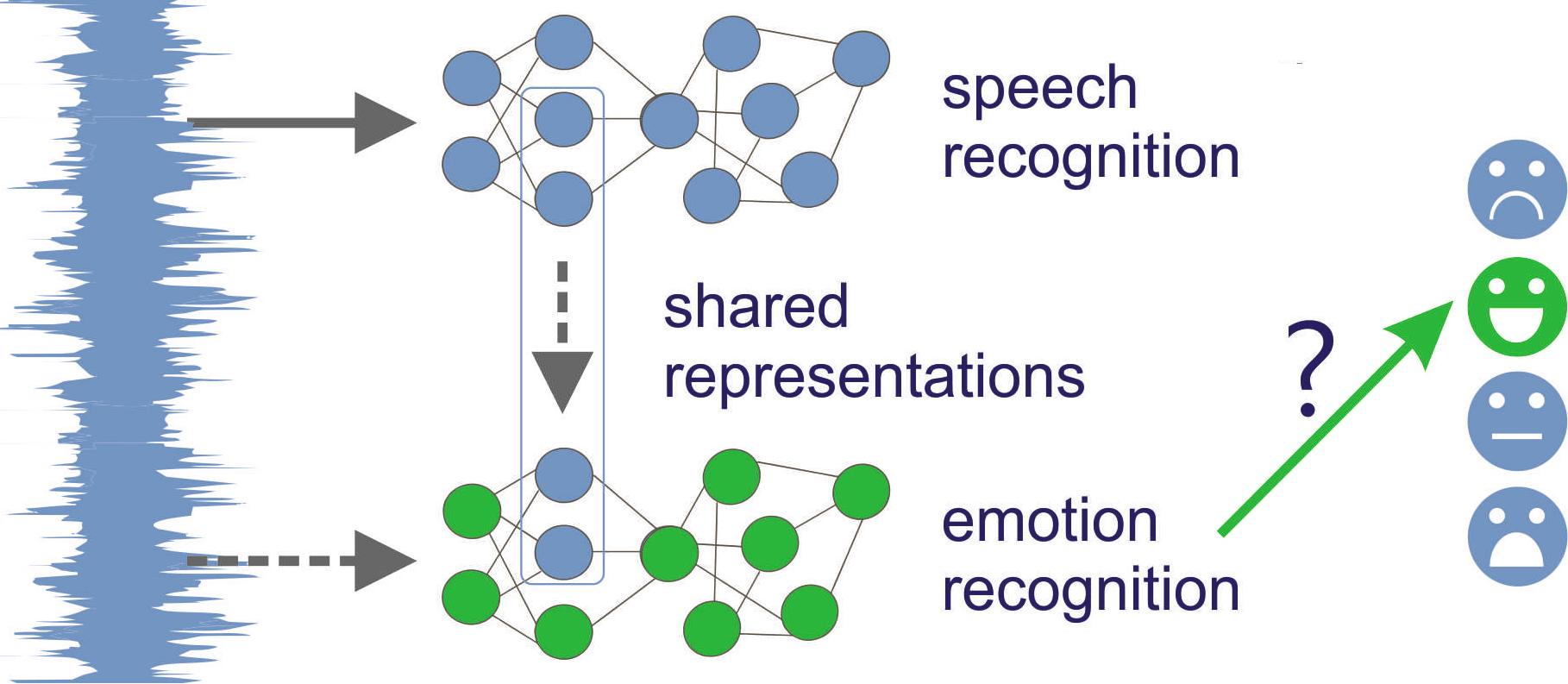
Acoustic emotion recognition aims to categorize the affective state of the speaker
and is still a difficult task for machine
learning models. The difficulties come
from the scarcity of training data, general
subjectivity in emotion perception resulting in low annotator agreement, and the
uncertainty about which features are the
most relevant and robust ones for classification. In this paper, we will tackle
the latter problem. Inspired by the recent success of transfer learning methods
we propose a set of architectures which
utilize neural representations inferred by
training on large speech databases for the
acoustic emotion recognition task. Our experiments on the IEMOCAP dataset show
10% relative improvements in the accuracy and F1-score over the baseline recurrent neural network which is trained endto-end for emotion recognition.
@InProceedings{LWMW17,
author = {Lakomkin, Egor and Weber, Cornelius and Magg, Sven and Wermter, Stefan},
title = {Reusing Neural Speech Representations for Auditory Emotion Recognition},
booktitle = {Proceedings of the Eighth International Joint Conference on Natural Language Processing},
journal = {None},
editors = {}
number = {}
volume = {1},
pages = {423--430},
year = {2017},
month = {Nov},
publisher = {ACL},
doi = {10.48550/arXiv.1803.11508},
url = {}
}