Recognition and Prediction of Human-Object Interactions with a Self-Organizing Architecture
Proceedings of the International Joint Conference on Neural Networks (IJCNN 2018) ,
pages 1197--1204,
doi: 10.1109/IJCNN.2018.8489178
- Jul 2018
Associated documents :


The recognition and prediction of human actions are
challenging perception tasks that require reasoning upon a large
space of fine-grained body motion patterns. In this work, we
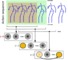
propose a hierarchical self-organizing architecture which jointly
learns to recognize and predict human-object interactions from
RGB-D videos. Our model consists of a hierarchy of GrowWhen-Required (GWR) networks which process and learn cooccurring actions and objects from the training data. Our goal
is to learn prototype body motion patterns when manipulating
objects as well as to internally store prototype transitions of
body postures over time. The architecture can generate sequences
of arbitrary length given an observed initial motion pattern as
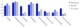
well as predict future action labels. Experimental results on
a dataset of daily activities demonstrate that our architecture
recognizes ongoing actions and predicts the upcoming ones with
high accuracy. The generated body pose trajectories demonstrate
that our architecture is suitable to be further applied to the
problem of the look-ahead planning of a robotic response in a
human-robot interaction scenario.




@InProceedings{MPW18,
author = {Mici, Luiza and Parisi, German I. and Wermter, Stefan},
title = {Recognition and Prediction of Human-Object Interactions with a Self-Organizing Architecture},
booktitle = {Proceedings of the International Joint Conference on Neural Networks (IJCNN 2018)},
journal = {None},
editors = {}
number = {}
volume = {}
pages = {1197--1204},
year = {2018},
month = {Jul},
publisher = {None},
doi = {10.1109/IJCNN.2018.8489178},
url = {None},
}