Combining Articulatory Features with End-to-end Learning in Speech Recognition
Proceedings of the International Conference on Artificial Neural Networks (ICANN),
doi: 10.1007/978-3-030-01424-7_49
- Oct 2018
Associated documents :


End-to-end neural networks have shown promising results on large
vocabulary continuous speech recognition (LVCSR) systems. However, it is
challenging to integrate domain knowledge into such systems. Specifically, articulatory features (AFs) which are inspired by the human speech production
mechanism can help in speech recognition. This paper presents two approaches
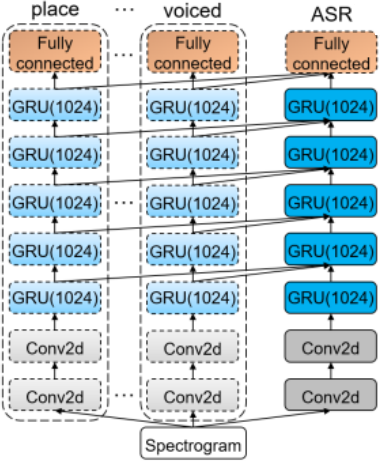
to incorporate domain knowledge into end-to-end training: (a) fine-tuning networks which reuse hidden layer representations of AF extractors as input for ASR
tasks; (b) progressive networks which combine articulatory knowledge by lateral
connections from AF extractors. We evaluate the proposed approaches on the
speech Wall Street Journal corpus and test on the eval92 standard evaluation dataset. Results show that both fine-tuning and progressive networks can integrate
articulatory information into end-to-end learning and outperform previous systems.
@InProceedings{QWLTW18,
author = {Qu, Leyuan and Weber, Cornelius and Lakomkin, Egor and Twiefel, Johannes and Wermter, Stefan},
title = {Combining Articulatory Features with End-to-end Learning in Speech Recognition},
booktitle = {Proceedings of the International Conference on Artificial Neural Networks (ICANN)},
journal = {None},
editors = {}
number = {}
volume = {}
pages = {}
year = {2018},
month = {Oct},
publisher = {Springer},
doi = {10.1007/978-3-030-01424-7_49},
url = {None},
}