Deep Reinforcement Learning using Compositional Representations for Performing Instructions
Paladyn. Journal of Behavioral Robotics,
Volume 9,
pages 358-–373,
doi: 10.1515/pjbr-2018-0026
- Nov 2018

Associated documents :


Spoken language is one of the most efficient ways
to instruct robots about performing domestic tasks. However, the state of the environment has to be considered to
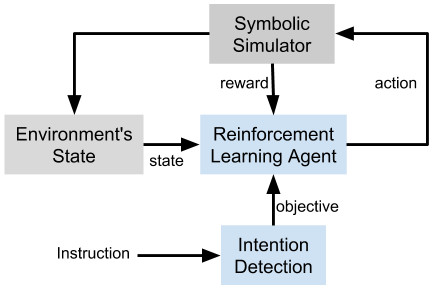
plan and execute actions successfully. We propose a system that learns to recognise the users intention and map
it to a goal. A reinforcement learning (RL) system then generates a sequence of actions toward this goal considering
the state of the environment. A novel contribution in this
paper is the use of symbolic representations for both input
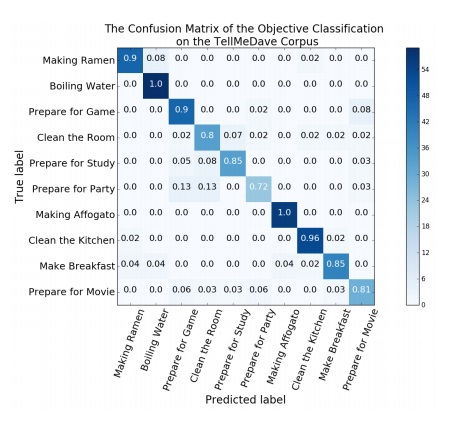
and output of a neural Deep Q-network (DQN), which enables it to be used in a hybrid system. To show the effectiveness of our approach, the Tell-Me-Dave corpus is used to
train an intention detection model and in a second step an
RL agent generates the sequences of actions towards the
detected objective, represented by a set of state predicates.
We show that the system can successfully recognise command sequences from this corpus as well as train the deepRL network with symbolic input. We further show that the
performance can be significantly increased by exploiting
the symbolic representation to generate intermediate rewards.
@Article{ZMWFW18,
author = {Zamani, Mohammad Ali and Magg, Sven and Weber, Cornelius and Fu, Di and Wermter, Stefan},
title = {Deep Reinforcement Learning using Compositional Representations for Performing Instructions},
booktitle = {None},
journal = {Paladyn. Journal of Behavioral Robotics},
editors = {None},
number = {}
volume = {9},
pages = {358-–373},
year = {2018},
month = {Nov},
publisher = {None},
doi = {10.1515/pjbr-2018-0026},
url = {None},
}