KT-Speech-Crawler: Automatic Dataset Construction for Speech Recognition from YouTube Videos
Proceedings of the Conference on Empirical Methods in Natural Language Processing,
pages 90--95,
doi: 10.18653/v1/D18-2016
- Jan 2018

Associated documents :


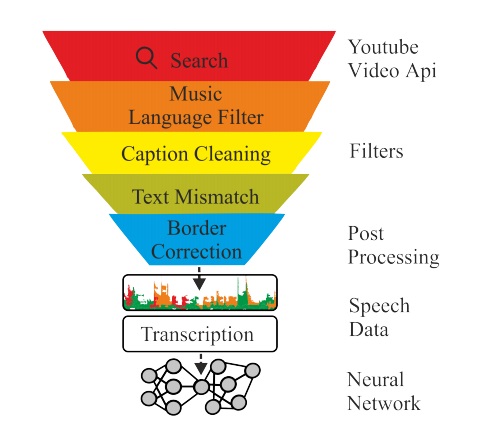
In this paper, we describe KT-Speech-Crawler:
an approach for automatic dataset construction
for speech recognition by crawling YouTube
videos. We outline several filtering and postprocessing steps, which extract samples that
can be used for training end-to-end neural
speech recognition systems. In our experiments, we demonstrate that a single-core version of the crawler can obtain around 150
hours of transcribed speech within a day, containing an estimated 3.5% word error rate
in the transcriptions. Automatically collected samples contain reading and spontaneous speech recorded in various conditions
including background noise and music, distant
microphone recordings, and a variety of accents and reverberation. When training a deep
neural network on speech recognition, we observed around 40% word error rate reduction
on the Wall Street Journal dataset by integrating 200 hours of the collected samples into the
training set. The demo1
and the crawler code2
are publicly available.
@InProceedings{LWMW18,
author = {Lakomkin, Egor and Weber, Cornelius and Magg, Sven and Wermter, Stefan},
title = {KT-Speech-Crawler: Automatic Dataset Construction for Speech Recognition from YouTube Videos},
booktitle = {Proceedings of the Conference on Empirical Methods in Natural Language Processing},
journal = {None},
editors = {}
number = {}
volume = {}
pages = {90--95},
year = {2018},
month = {Jan},
publisher = {Association for Computational Lingustics},
doi = {10.18653/v1/D18-2016},
url = {None},
}