LipSound: Neural Mel-spectrogram Reconstruction for Lip Reading
The 20th Annual Conference of the International Speech Communication Association (INTERSPEECH 2019),
doi: 10.21437/Interspeech.2019-1393
- Sep 2019

Associated documents :


Lip reading, also known as visual speech recognition, has recently received considerable attention. Although advanced feature engineering and powerful deep neural network architectures have been proposed for this task, the performance still cannot be competitive with speech recognition tasks using the audio
modality as input. This is mainly because compared with audio,
visual features carry less information relevant to word recognition. For example, the voiced sound made while the vocal cords
vibrate can be represented by audio but is not reflected by mouth
or lip movement. In this paper, we map the sequence of mouth
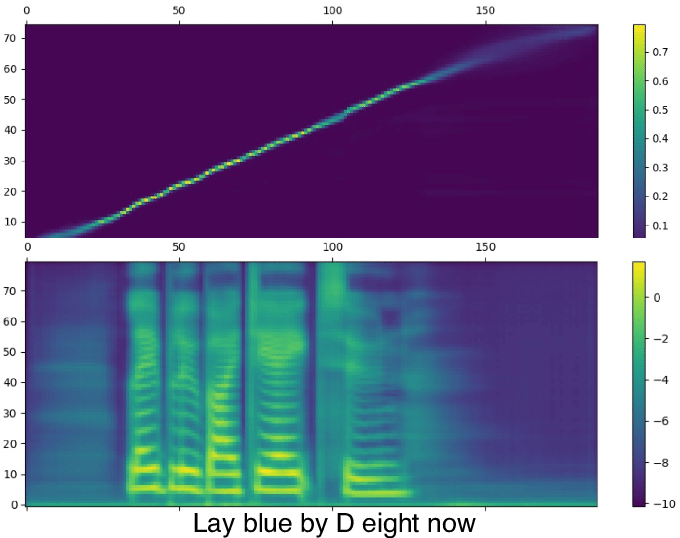
movement images directly to mel-spectrogram to reconstruct
the speech relevant information. Our proposed architecture
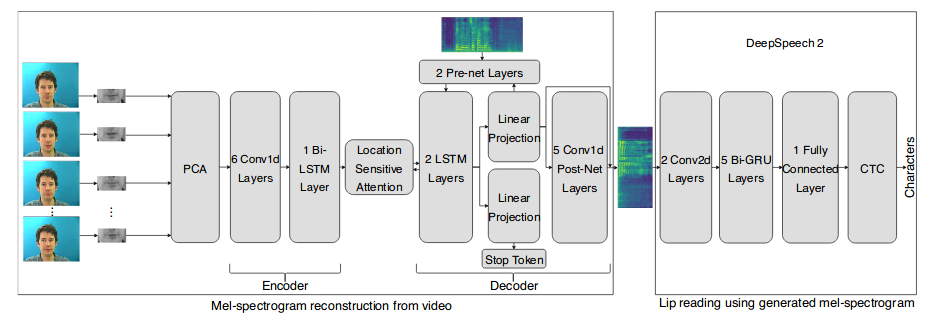
consists of two components: (a) the mel-spectrogram reconstruction front-end which includes an encoder-decoder architecture with attention mechanism to predict mel-spectrogram from
videos; (b) the lip reading back-end consisting of convolutional
layers, bi-directional gated recurrent units, and connectionist
temporal classification loss, which consumes the generated melspectrogram representation to predict text transcriptions. The
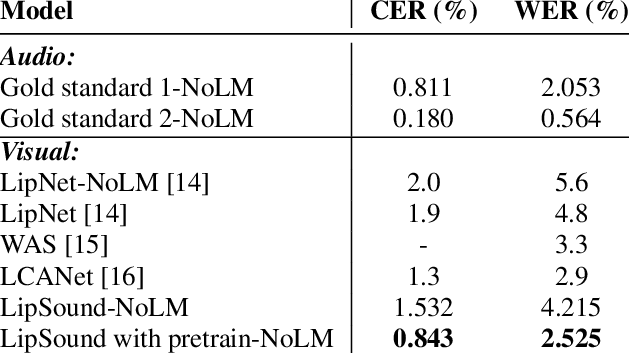
speaker-dependent evaluation results demonstrate that our proposed model not only generates quality mel-spectrograms but
also outperforms state-of-the-art models on the GRID benchmark lip reading dataset, with 0.843% character error rate and
2.525% word error rate.

@InProceedings{QWW19,
author = {Qu, Leyuan and Weber, Cornelius and Wermter, Stefan},
title = {LipSound: Neural Mel-spectrogram Reconstruction for Lip Reading},
booktitle = {The 20th Annual Conference of the International Speech Communication Association (INTERSPEECH 2019)},
journal = {None},
editors = {}
number = {}
volume = {}
pages = {}
year = {2019},
month = {Sep},
publisher = {IEEE},
doi = {10.21437/Interspeech.2019-1393},
url = {None},
}