Planning-integrated Policy for Efficient Reinforcement Learning in Sparse-reward Environments
Proceedings of the International Joint Conference on Neural Networks (IJCNN 2021),
- Jul 2021
Associated documents :

Model-free reinforcement learning algorithms can
learn an optimal policy from experience without requiring prior
knowledge. However, model-free agents require vast amounts
of samples, particularly in sparse reward environments where
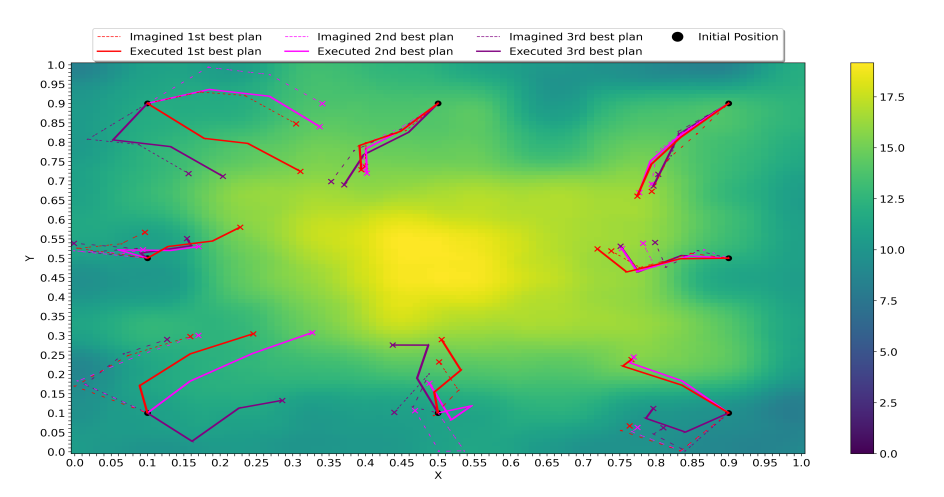
most states contain zero rewards. We developed a model-based
approach to tackle the high sample complexity problem in sparse
reward settings with continuous actions. A trained world model
is queried by a particle swarm optimization (PSO) planner and
employed as the action selection mechanism, hence taking the
role of the actor in an actor-critic architecture. Parameters of
the PSO regulate the agent's exploration rate. We show that
the planner aids the agent to discover rewards even in regions
with zero value gradient. Our simple planning integrated policy
architecture learns more efficiently with fewer samples than
continuous model-free algorithms.
@InProceedings{WWW21,
author = {Wulur, Christoper and Weber, Cornelius and Wermter, Stefan},
title = {Planning-integrated Policy for Efficient Reinforcement Learning in Sparse-reward Environments},
booktitle = {Proceedings of the International Joint Conference on Neural Networks (IJCNN 2021)},
journal = {None},
editors = {}
number = {}
volume = {}
pages = {}
year = {2021},
month = {Jul},
publisher = {IEEE},
doi = {}
url = {None},
}