FaVoA: Face-Voice Association Favours Ambiguous Speaker Detection
Proceedings of the 30th International Conference on Artificial Neural Networks (ICANN 2021),
Editors: Igor Farkaš, Paolo Masulli, Sebastian Otte, Stefan Wermter,
Volume LNCS 12891,
pages 439--450,
doi: 10.1007/978-3-030-86362-3_36
- Sep 2021
Associated documents :


<!doctype html>
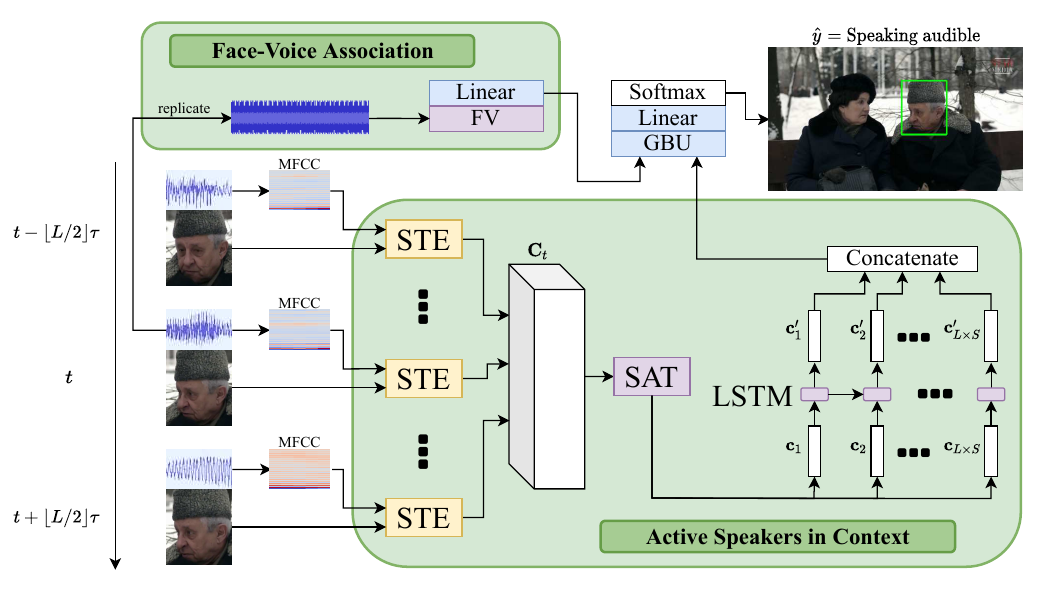
The strong relation between face and voice can aid active speaker detection systems when faces are visible, even in difficult settings, when the face of a speaker is not clear or when there are several people in the same scene. By being capable of estimating the frontal facial representation of a person from his/her speech, it becomes easier to determine whether he/she is a potential candidate for being classified as an active speaker, even in challenging cases in which no mouth movement is detected from any person in that same scene. By incorporating a face-voice association neural network into an existing state-of-the-art active speaker detection model, we introduce FaVoA (<b>Fa</b>ce-<b>Vo</b>ice Association <b>A</b>mbiguous Speaker Detector), a neural network model that can correctly classify particularly ambiguous scenarios. FaVoA not only finds positive associations, but helps to rule out non-matching face-voice associations, where a face does not match a voice. Its use of a gated-bimodal-unit architecture for the fusion of those models offers a way to quantitatively determine how much each modality contributes to the classification.
@InProceedings{CWW21,
author = {Carneiro, Hugo and Weber, Cornelius and Wermter, Stefan},
title = {FaVoA: Face-Voice Association Favours Ambiguous Speaker Detection},
booktitle = {Proceedings of the 30th International Conference on Artificial Neural Networks (ICANN 2021)},
journal = {None},
editors = {Igor Farkaš, Paolo Masulli, Sebastian Otte, Stefan Wermter},
number = {}
volume = {LNCS 12891},
pages = {439--450},
year = {2021},
month = {Sep},
publisher = {Springer Nature},
doi = {10.1007/978-3-030-86362-3_36},
url = {None},
}