Word-by-Word Generation of Visual Dialog using Reinforcement Learning
Proceedings of the 31st International Conference on Artificial Neural Networks (ICANN 2022),
pages 123--135,
doi: 10.1007/978-3-031-15931-2_11
- Sep 2022
Associated documents :


The task of visual dialog generation requires an agent holding a conversation referencing question history, putting the current question into context, and processing visual content. While previous research focused on arranging questions to form dialog, we tackle the more challenging task of arranging questions from words, and dialog from questions. We develop our model in a simple âGuess which?â game scenario where the agent needs to predict an image region that has been selected by an oracle by asking questions to the oracle. As a result, the reinforcement learning agent arranges words to refer to the image features strategically to acquire the required information from the oracle, memorizing it and giving the correct prediction with an accuracy well above 80%. Imposing costs on the number of questions asked to the oracle leads to a strategy using few questions, while imposing costs on the number of words used leads to more but shorter questions. Our results are a step towards making goal-directed dialog fully generic by assembling it from words, elementary constituents of language.
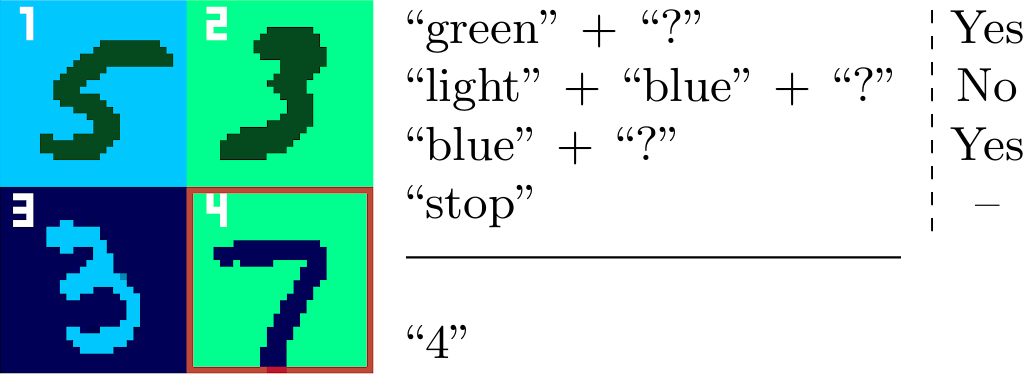
@InProceedings{LWBW22,
author = {Lysa, Yuliia and Weber, Cornelius and Becker, Dennis and Wermter, Stefan},
title = {Word-by-Word Generation of Visual Dialog using Reinforcement Learning},
booktitle = {Proceedings of the 31st International Conference on Artificial Neural Networks (ICANN 2022)},
journal = {None},
editors = {}
number = {}
volume = {}
pages = {123--135},
year = {2022},
month = {Sep},
publisher = {Springer International Publishing},
doi = {10.1007/978-3-031-15931-2_11},
url = {None},
}