Whose Emotion Matters? Speaker Detection without Prior Knowledge
arXiv:2211.15377,
doi: 10.48550/arXiv.2211.15377
- Dec 2022
Associated documents :


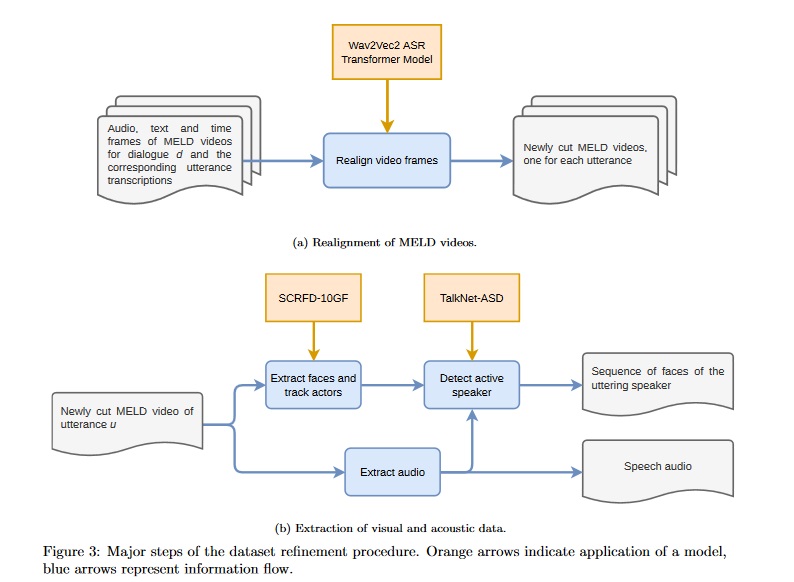
The task of emotion recognition in conversations (ERC) benefits from the availability of multiple modalities, as offered, for example, in the video-based MELD dataset. However, only a few research approaches use both acoustic and visual information from the MELD videos. There are two reasons for this: First, label-to-video alignments in MELD are noisy, making those videos an unreliable source of emotional speech data. Second, conversations can involve several people in the same scene, which requires the detection of the person speaking the utterance. In this paper we demonstrate that by using recent automatic speech recognition and active speaker detection models, we are able to realign the videos of MELD, and capture the facial expressions from uttering speakers in 96.92% of the utterances provided in MELD. Experiments with a self-supervised voice recognition model indicate that the realigned MELD videos more closely match the corresponding utterances offered in the dataset. Finally, we devise a model for emotion recognition in conversations trained on the face and audio information of the MELD realigned videos, which outperforms state-of-the-art models for ERC based on vision alone. This indicates that active speaker detection is indeed effective for extracting facial expressions from the uttering speakers, and that faces provide more informative visual cues than the visual features state-of-the-art models have been using so far.


@Article{CWW22,
author = {Carneiro, Hugo and Weber, Cornelius and Wermter, Stefan},
title = {Whose Emotion Matters? Speaker Detection without Prior Knowledge},
booktitle = {None},
journal = {arXiv:2211.15377},
editors = {None},
number = {}
volume = {}
pages = {}
year = {2022},
month = {Dec},
publisher = {None},
doi = {10.48550/arXiv.2211.15377},
url = {None},
}