Embodying language models in robot action
Proceedings of the 32nd European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN 2024),
pages 625--630,
doi: 10.14428/esann/2024.es2024-143
- Oct 2024
Associated documents :


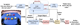
Large language models (LLMs) have achieved significant recent success in deep learning. The remaining challenges in robotics and human-robot interaction (HRI) still need to be tackled but off-the-shelf pre-trained LLMs with advanced language and reasoning capabilities can provide solutions to problems in the field. In this work, we realise an open-ended HRI scenario involving a humanoid robot communicating with a human while performing robotic object manipulation tasks at a table. To this end, we combine pre-trained general models of speech recognition, vision-language, text-to-speech and open-world object detection with robot-specific models of visuospatial coordinate transfer and inverse kinematics, as well as a task-specific motion model. Our experiments reveal robust performance by the language model in accurately selecting the task mode and by the whole model in correctly executing actions during open-ended dialogue. Our innovative architecture enables a seamless integration of open-ended dialogue, scene description, open-world object detection and action execution. It is promising as a modular solution for diverse robotic platforms and HRI scenarios.
@InProceedings{GOWW24,
author = {Gaede, Connor and Özdemir, Ozan and Weber, Cornelius and Wermter, Stefan},
title = {Embodying language models in robot action},
booktitle = {Proceedings of the 32nd European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN 2024)},
journal = {}
editors = {}
number = {}
volume = {}
pages = {625--630},
year = {2024},
month = {Oct},
publisher = {Ciaco - i6doc.com},
doi = {10.14428/esann/2024.es2024-143},
}