Curriculum goal masking for continuous deep reinforcement learning
2019 Joint IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob),
pages 183--188,
doi: 10.1109/DEVLRN.2019.8850721
- Aug 2019
Associated documents :


Deep reinforcement learning has recently gained a
focus on problems where policy or value functions are based on
universal value function approximators (UVFAs) which renders
them independent of goals. Evidence exists that the sampling of
goals has a strong effect on the learning performance, and the
problem of optimizing the goal sampling is frequently tackled
with intrinsic motivation methods. However, there is a lack of
general mechanisms that focus on goal sampling in the context
of deep reinforcement learning based on UVFAs. In this work,
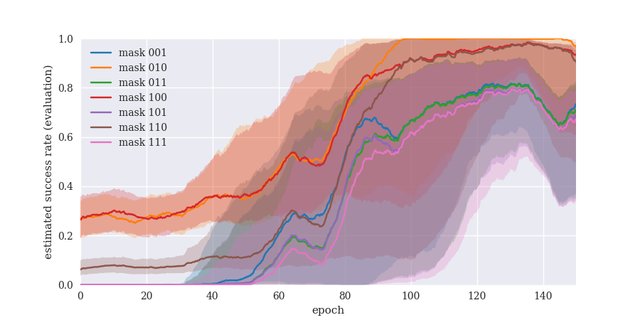
we introduce goal masking as a method to estimate a goalâs
difficulty level and to exploit this estimation to realize curriculum
learning. Our results indicate that focusing on goals with a
medium difficulty level is appropriate for deep deterministic
policy gradient (DDPG) methods, while an âaim for the stars
and reach the moon-strategyâ, where difficult goals are sampled
much more often than simple goals, leads to the best learning
performance in cases where DDPG is combined with hindsight
experience replay (HER).
@InProceedings{EMW19,
author = {Eppe, Manfred and Magg, Sven and Wermter, Stefan},
title = {Curriculum goal masking for continuous deep reinforcement learning},
booktitle = {2019 Joint IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob)},
journal = {None},
editors = {}
number = {}
volume = {}
pages = {183--188},
year = {2019},
month = {Aug},
publisher = {IEEE},
doi = {10.1109/DEVLRN.2019.8850721},
url = {None},
}